 Tweet
Tweet
มันน่าจะเป็นคำถามที่น่าสงสัยสำหรับหลายๆคนวันนี้ผมเข้าใจและ ยืมเนื้อหาบางส่วนมาจากVmodtechคับ
Loop Stream Detector ในซีพียูตระกูล Core i7
ใน ซีพียูตระกูล Core i7 อินเทลได้ทำย้ายตำแหน่งของ Loop Stream Detector ใหม่ เพื่อมาเก็บข้อมูลที่ได้จากการ Decode แล้ว ทำให้สามารถลดขั้นตอนการทำงานของซีพียูลงได้อีก 2 ขั้นตอนครับ เพราะหากซีพียูทำการ Excecute เสร็จ ซีพียูต้องการทำคำสั่งต่อไป ซีพียูก็มาเอาคำสั่งที่ถูก Decode เรียบร้อยซึ่งถูกเก็บอยู่ใน Loop Stream Detector ไป Execute ได้เลยครับ ไม่ต้อง Decode และ Fetch ใหม่ นอกเสียจากว่าคำสั่งนั้นๆจะไม่อยู่ใน Loop Stream Detector ครับ
นอก จากนี้ อินเทลยังได้เพิ่มขนาดของ Loop Stream Detector ให้สามารถเก็บคำสั่งเพิ่มขึ้นจากเดิมที่เคยเก็บได้เพียง 18 คำสั่ง มาเป็น 28 คำสั่งครับ
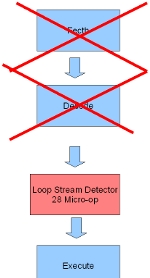
ดังนั้นพวกโปรแกรมSuper PI หรือ Encode Program นั้นเป็นการทำงานแบบวน Loop
การทำงานแบบวนLoopก็คือทำซ้ำไปเรื่อยๆจนกว่าจะจบเงื่อนไขนั่นเอง ดังนั้นเมื่อมีการใช้คำสั่งซ้ำๆๆๆ i7จึงไม่ต้องไปเรียกข้อมูลจากAll Levels Cache
เหมือนกับเราจะใช้ดินสอมาเขียนอะไรซักอย่าง ถ้าเป็นi7 ก็เหมือนมันวางอยู่ข้างๆมือเราจาเอามาใช้เมื่อไรก็ได้พอเขียนเส็ดตามที่ต้องการแล้วจาเขียนต่อก็หยิบมาเขียนต่อได้เลย
แต่ถ้าเป็นPhenom จะเหมือนกับต้องเดินออกไปนอกบ้านเพื่อไปหาและไปหยิบดินสอมาเขียน
พอเขียนเส็ดตามที่ต้องการแล้วดินสอก็จะหายไป จะเขียนใหม่ก็ต้องออกไปหาและหยิบจากนอกบ้านอีก
แต่ถ้าโปรแกรมไหนที่มีการเปลี่ยนแปลงคำสั่งบ่อยๆ ความเร็วการประมวลผลจึงไม่แตกต่างกันเท่าไร
สำหรับ K10 Micro-Architecture นั้น ได้มีการพัฒนาให้สามารถดึง (Fetch) ชุดคำสั่งจาก L1I Cache ได้มากกว่าเดิมเท่าตัว จาก 16-byte blocks ใน K8 เป็น 32-byte blocks ใน K10 เนื่องจากขนาดชุดคำสั่งในทุกวันนี้มีขนาดใหญ่ขึ้นกว่าเดิม ทำให้การขยายขนาดการดึงชุดคำสั่งช่วยลดปัญหาคอขวดได้เป็นอย่างดี แต่ไม่มี Loop Stream Detector เหมือนi7 ทำให้การทำงานเป็นไปแบบต้องค้นหาคำสั่งใหม่อยู่เรื่อย

แต่ไม่ใช่ว่าไม่ดี เช่นบางการทดสอบที่Phenomเร็วกว่านั้นก็เป็นเพราะยังไงก็ต้องหาคำสั่งใหม่อยู่ตลอดอยู่แล้วไม่ต้องมาเสียเวลาตรวจสอบใน Loop Stream Detector ว่ามีคำสั่งที่ต้องใช้อยู่หรือไม่ ทำให้บางโปรแกรมPhenomกลับทำได้ดีกว่าในสัญญาณนาฬิกาเดียวกันคับ
แต่ก็ถือว่าน้อย เพราะโปรแกรมที่มาทดสอบต่างๆส่วนมากล้วนเป็นการทำงานแบบLoopทั้งสิ้น
ก็คือคำสั่งเดียวหรือไกล้เคียงกัน ทำงานไปเรื่อยๆจนจบคำสั่งคับ
ส่วนเกมส์ใหม่ๆที่Phenomทำงานได้ช้ากว่าจากขนาดชุดคำสั่งที่ใหญ่ขึ้น คาดว่าเป็นเพราะL3ที่มีเพียง2MBคับ
ส่วนที่มันต่างกันมากน้อยนั้นผมคิดว่าคงเป็นเพราะโครงสร้างของชุดคำสั่งที่แตกต่าง
รวมไปถึงการจัดวางLayoutของทรานซิสเตอร์ตัวต่างๆด้วยคับ
และถ้าทั้งคู่พัฒนาBranch Target Buffer (BTB)
ก็คือการคาดเดาคำสั่งล่วงหน้าได้ดีมากขึ้นเนี่ยก็จะเร็วขึ้นเป็นเงาตามตัวคับ
ถ้าผิดพลาดยังไงก็ขอโทษด้วยนะคับ แต่ผมก็วิเคราะห์ตามที่ผมได้เรียนมาเท่านั้นอะคับ
Loop Stream Detector ในซีพียูตระกูล Core i7
ใน ซีพียูตระกูล Core i7 อินเทลได้ทำย้ายตำแหน่งของ Loop Stream Detector ใหม่ เพื่อมาเก็บข้อมูลที่ได้จากการ Decode แล้ว ทำให้สามารถลดขั้นตอนการทำงานของซีพียูลงได้อีก 2 ขั้นตอนครับ เพราะหากซีพียูทำการ Excecute เสร็จ ซีพียูต้องการทำคำสั่งต่อไป ซีพียูก็มาเอาคำสั่งที่ถูก Decode เรียบร้อยซึ่งถูกเก็บอยู่ใน Loop Stream Detector ไป Execute ได้เลยครับ ไม่ต้อง Decode และ Fetch ใหม่ นอกเสียจากว่าคำสั่งนั้นๆจะไม่อยู่ใน Loop Stream Detector ครับ
นอก จากนี้ อินเทลยังได้เพิ่มขนาดของ Loop Stream Detector ให้สามารถเก็บคำสั่งเพิ่มขึ้นจากเดิมที่เคยเก็บได้เพียง 18 คำสั่ง มาเป็น 28 คำสั่งครับ
ดังนั้นพวกโปรแกรมSuper PI หรือ Encode Program นั้นเป็นการทำงานแบบวน Loop
การทำงานแบบวนLoopก็คือทำซ้ำไปเรื่อยๆจนกว่าจะจบเงื่อนไขนั่นเอง ดังนั้นเมื่อมีการใช้คำสั่งซ้ำๆๆๆ i7จึงไม่ต้องไปเรียกข้อมูลจากAll Levels Cache
เหมือนกับเราจะใช้ดินสอมาเขียนอะไรซักอย่าง ถ้าเป็นi7 ก็เหมือนมันวางอยู่ข้างๆมือเราจาเอามาใช้เมื่อไรก็ได้พอเขียนเส็ดตามที่ต้องการแล้วจาเขียนต่อก็หยิบมาเขียนต่อได้เลย
แต่ถ้าเป็นPhenom จะเหมือนกับต้องเดินออกไปนอกบ้านเพื่อไปหาและไปหยิบดินสอมาเขียน
พอเขียนเส็ดตามที่ต้องการแล้วดินสอก็จะหายไป จะเขียนใหม่ก็ต้องออกไปหาและหยิบจากนอกบ้านอีก
แต่ถ้าโปรแกรมไหนที่มีการเปลี่ยนแปลงคำสั่งบ่อยๆ ความเร็วการประมวลผลจึงไม่แตกต่างกันเท่าไร
สำหรับ K10 Micro-Architecture นั้น ได้มีการพัฒนาให้สามารถดึง (Fetch) ชุดคำสั่งจาก L1I Cache ได้มากกว่าเดิมเท่าตัว จาก 16-byte blocks ใน K8 เป็น 32-byte blocks ใน K10 เนื่องจากขนาดชุดคำสั่งในทุกวันนี้มีขนาดใหญ่ขึ้นกว่าเดิม ทำให้การขยายขนาดการดึงชุดคำสั่งช่วยลดปัญหาคอขวดได้เป็นอย่างดี แต่ไม่มี Loop Stream Detector เหมือนi7 ทำให้การทำงานเป็นไปแบบต้องค้นหาคำสั่งใหม่อยู่เรื่อย
แต่ไม่ใช่ว่าไม่ดี เช่นบางการทดสอบที่Phenomเร็วกว่านั้นก็เป็นเพราะยังไงก็ต้องหาคำสั่งใหม่อยู่ตลอดอยู่แล้วไม่ต้องมาเสียเวลาตรวจสอบใน Loop Stream Detector ว่ามีคำสั่งที่ต้องใช้อยู่หรือไม่ ทำให้บางโปรแกรมPhenomกลับทำได้ดีกว่าในสัญญาณนาฬิกาเดียวกันคับ
แต่ก็ถือว่าน้อย เพราะโปรแกรมที่มาทดสอบต่างๆส่วนมากล้วนเป็นการทำงานแบบLoopทั้งสิ้น
ก็คือคำสั่งเดียวหรือไกล้เคียงกัน ทำงานไปเรื่อยๆจนจบคำสั่งคับ
ส่วนเกมส์ใหม่ๆที่Phenomทำงานได้ช้ากว่าจากขนาดชุดคำสั่งที่ใหญ่ขึ้น คาดว่าเป็นเพราะL3ที่มีเพียง2MBคับ
ส่วนที่มันต่างกันมากน้อยนั้นผมคิดว่าคงเป็นเพราะโครงสร้างของชุดคำสั่งที่แตกต่าง
รวมไปถึงการจัดวางLayoutของทรานซิสเตอร์ตัวต่างๆด้วยคับ
และถ้าทั้งคู่พัฒนาBranch Target Buffer (BTB)
ก็คือการคาดเดาคำสั่งล่วงหน้าได้ดีมากขึ้นเนี่ยก็จะเร็วขึ้นเป็นเงาตามตัวคับ
ถ้าผิดพลาดยังไงก็ขอโทษด้วยนะคับ แต่ผมก็วิเคราะห์ตามที่ผมได้เรียนมาเท่านั้นอะคับ
 ขอบคุณครับ ไม่รู้ว่ามันเป็นจริงหรือไม่ แต่ก็ถือว่าเป็นข้อมูลที่ดีครับ
ขอบคุณครับ ไม่รู้ว่ามันเป็นจริงหรือไม่ แต่ก็ถือว่าเป็นข้อมูลที่ดีครับ


Comment