


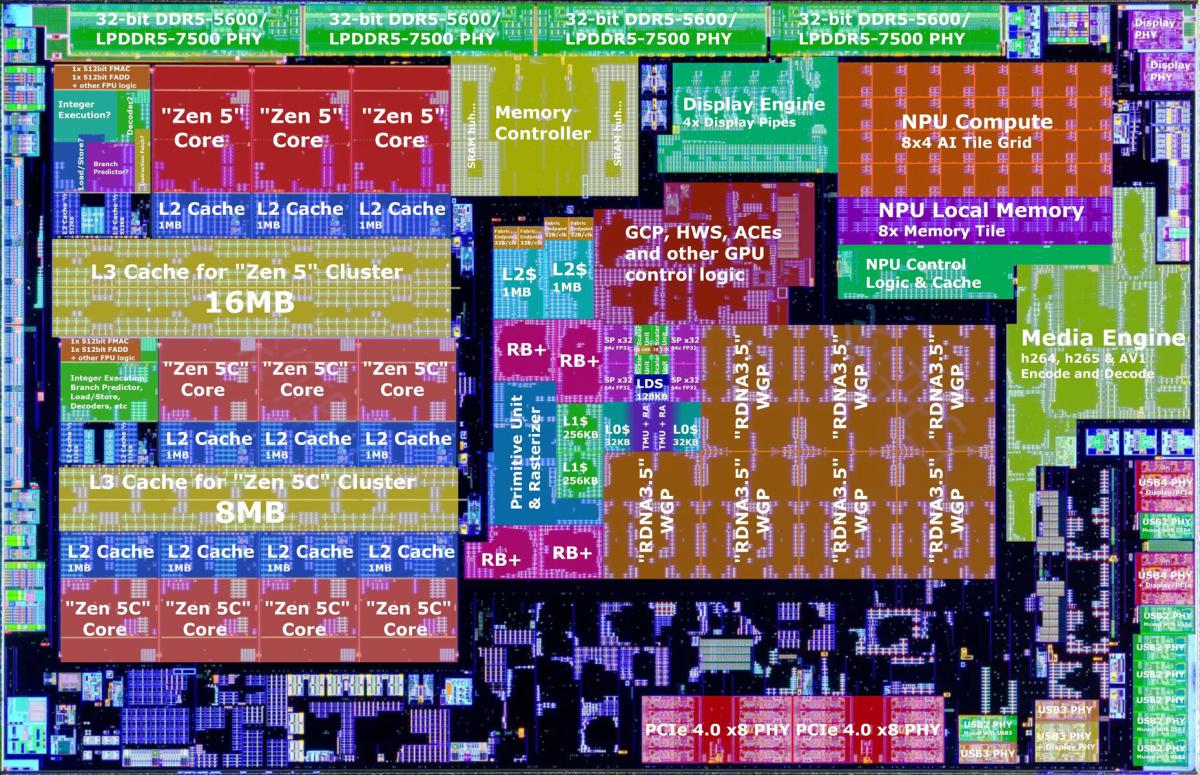
ช็อตแรกของโปรเซสเซอร์ "Strix Point" ขนาด 4 นาโนเมตรตัวใหม่ของ AMD ได้ถูกเปิดเผยออกมา โดยต้องขอบคุณผู้ที่ชื่นชอบบนโซเชียลมีเดียของจีน "Strix Point" เป็นไดที่มีขนาดใหญ่กว่า "Phoenix" อย่างเห็นได้ชัด โดยวัดได้ 12.06 มม. x 18.71 มม. (ยาว x กว้าง) เมื่อเทียบกับ "Phoenix" ที่วัดได้ 9.06 มม. x 15.01 มม. ขนาดของไดที่เพิ่มขึ้นนี้ส่วนใหญ่มาจาก CPU, iGPU และ NPU ที่ใหญ่ขึ้น กระบวนการนี้ได้รับการปรับปรุงจาก TSMC N4 บน "Phoenix" และ "Hawk Point" ที่เป็นรุ่นย่อย ไปจนถึงโหนด TSMC N4P ที่ใหม่กว่า
Nemez (GPUsAreMagic) ได้อธิบายไดช็อตอย่างละเอียดถี่ถ้วนเกี่ยวกับไดช็อตนี้ ปัจจุบัน CPU มี 12 คอร์ที่กระจายอยู่ใน CCX สองชุด โดยชุดหนึ่งมีคอร์ "Zen 5" สี่คอร์ที่แชร์แคช L3 ขนาด 16 MB และอีกชุดหนึ่งมีคอร์ "Zen 5c" แปดคอร์ที่แชร์แคช L3 ขนาด 8 MB CCX ทั้งสองเชื่อมต่อกับส่วนที่เหลือของชิปผ่าน Infinity Fabric iGPU ที่ค่อนข้างใหญ่จะครอบครองพื้นที่ตรงกลางของไดย์ โดยอิงตามสถาปัตยกรรมกราฟิก RDNA 3.5 และมีโปรเซสเซอร์เวิร์กกรุ๊ป (WGP) 8 ตัว หรือหน่วยประมวลผล (CU) 16 หน่วยที่เทียบเท่ากับโปรเซสเซอร์สตรีม 1,024 ตัว ส่วนประกอบสำคัญอื่นๆ ได้แก่ แบ็กเอนด์การเรนเดอร์ 4 ตัวที่เทียบเท่ากับ ROP 16 หน่วย และลอจิกควบคุม GPU มีแคช L2 ขนาด 2 MB ของตัวเองซึ่งรองรับการถ่ายโอนไปยัง Infinity Fabric
ส่วนประกอบที่เกี่ยวข้องซึ่งแยกจาก iGPU เล็กน้อยคือ Media Engine และ Display Engine Media Engine มอบการเร่งความเร็วด้วยฮาร์ดแวร์สำหรับการเข้ารหัสและถอดรหัส h.264, h.265 และ AV1 นอกเหนือจากรูปแบบวิดีโอเก่าๆ หลายรูปแบบ Display Engine มีหน้าที่เข้ารหัสเอาต์พุตเฟรมของ iGPU ไปยังรูปแบบตัวเชื่อมต่อต่างๆ (เช่น DisplayPort, eDP, HDMI) รวมถึงการบีบอัดสตรีมการแสดงผลที่เร่งความเร็วด้วยฮาร์ดแวร์ ในขณะที่ PHY ของจอภาพจะจัดการเลเยอร์ทางกายภาพของตัวเชื่อมต่อ
NPU เป็นส่วนประกอบตรรกะหลักลำดับที่สามของ "Strix Point" NPU รุ่นที่สองนี้โดย AMD มีขนาดใหญ่กว่าที่พบใน "Phoenix" อย่างเห็นได้ชัด NPU นี้ใช้สถาปัตยกรรม XDNA 2 ขั้นสูงกว่า และมีไทล์ AI เอนจิ้น 32 ตัวที่สื่อสารกับหน่วยความจำภายในความเร็วสูงของตัวเอง และตรรกะควบคุมที่เชื่อมต่อกับ Infinity Fabric NPU นี้ได้รับการออกแบบมาเพื่อตอบสนองและเกินข้อกำหนดฮาร์ดแวร์ของ Microsoft Copilot+ และให้ปริมาณงาน 50 TOPS
ตัวควบคุมหน่วยความจำรองรับ DDR5 แบบดูอัลแชนเนล (160 บิต) พร้อม DDR5-5600 ดั้งเดิม และ LPDDR5 128 บิตที่ความเร็วสูงสุดถึง LPDDR5-7500 ตัวควบคุมมีแคช SRAM ที่ไม่ระบุขนาด ซึ่ง Nemez สังเกตว่าพบเห็นในไดย์ "Phoenix 2" และ "Phoenix" เช่นกัน แต่ไม่พบในตัวควบคุมหน่วยความจำของ cIOD ที่พบใน "Raphael" และ "Dragon Range"
ซิลิกอน "Strix Point" มีรูทคอมเพล็กซ์ PCIe ขนาดเล็กกว่า "Phoenix" ซึ่งในทางกลับกันก็มีรูทคอมเพล็กซ์ขนาดเล็กกว่า "Cezanne" AMD ได้ลดจำนวนเลน PCIe ลง 4 เลนในช่วงสามเจเนอเรชันที่ผ่านมา "Cezanne" มีเลน PCIe Gen 3 จำนวน 24 เลน (บัสชิปเซ็ต x16 PEG + x4 NVMe + x4 หรือ GPP) ในขณะที่ "Phoenix" ตัดให้เหลือ 20 เลน PCIe Gen 4 (บัสชิปเซ็ต x8 PEG + x4 NVMe + x4 หรือ GPP + x4 ที่กำหนดค่าเป็น USB4) "Strix Point" รุ่นใหม่ลดจำนวนเลน PCIe Gen 4 ลงเหลือเพียง 16 เลน (x8 PEG + x4 NVMe + x4 กำหนดค่าเป็น USB4 หรือ GPP)
แนวคิดเบื้องหลังการลดเลน PCIe คือ "Strix Point" ได้รับการออกแบบมาให้แข่งขันกับ "Lunar Lake" ซึ่งมี x4 สำหรับ PEG/GPP เท่านั้น และเมื่อ "Arrow Lake-H" และ "Arrow Lake-HX" เข้าสู่ตลาดในที่สุด ก็จะพบกับชิป "Fire Range" ของ AMD ที่มีอินเทอร์เฟซ PCIe Gen 5 28 เลน และสามารถจับคู่กับ GPU มือถือแบบแยกที่เร็วที่สุดได้
ที่มา : TechPowerUp
ที่มา : TechPowerUp
