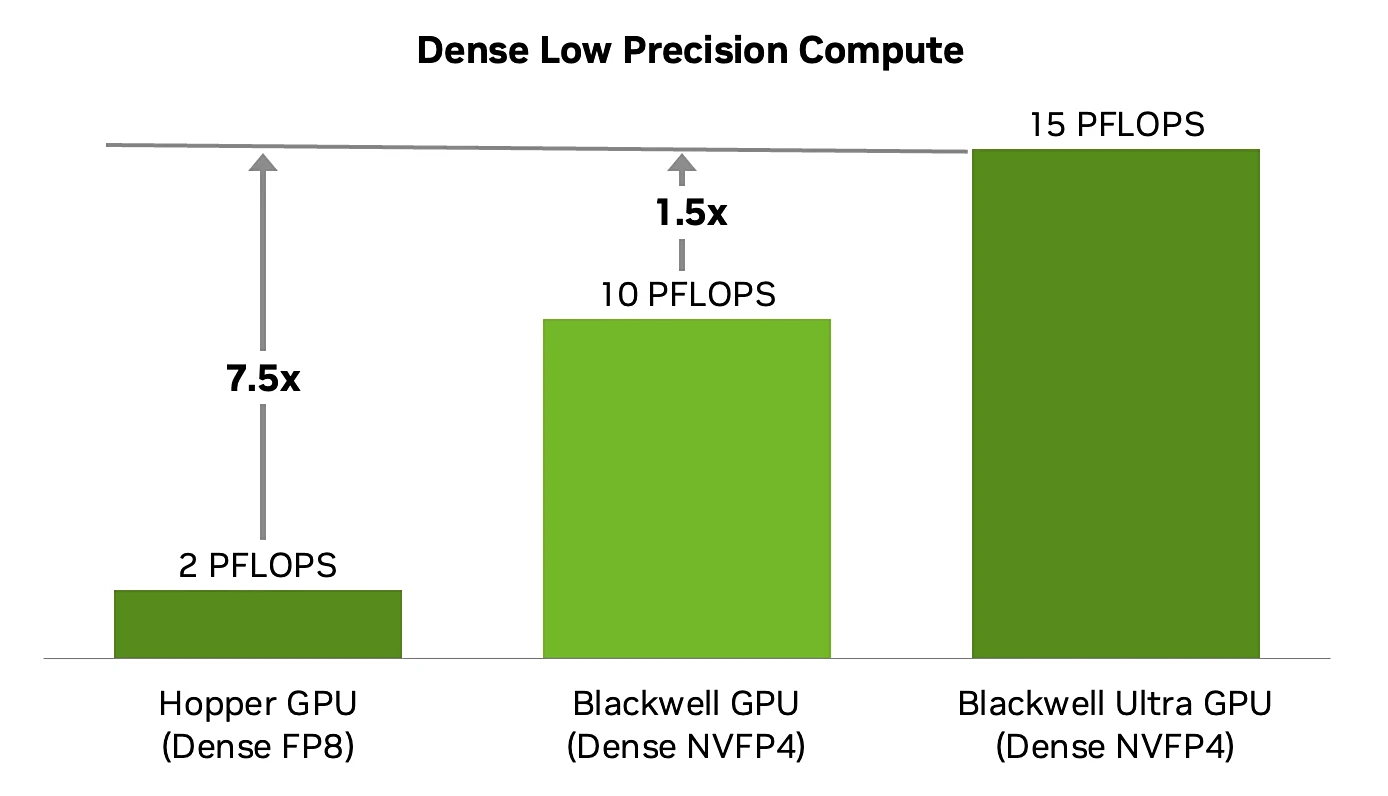
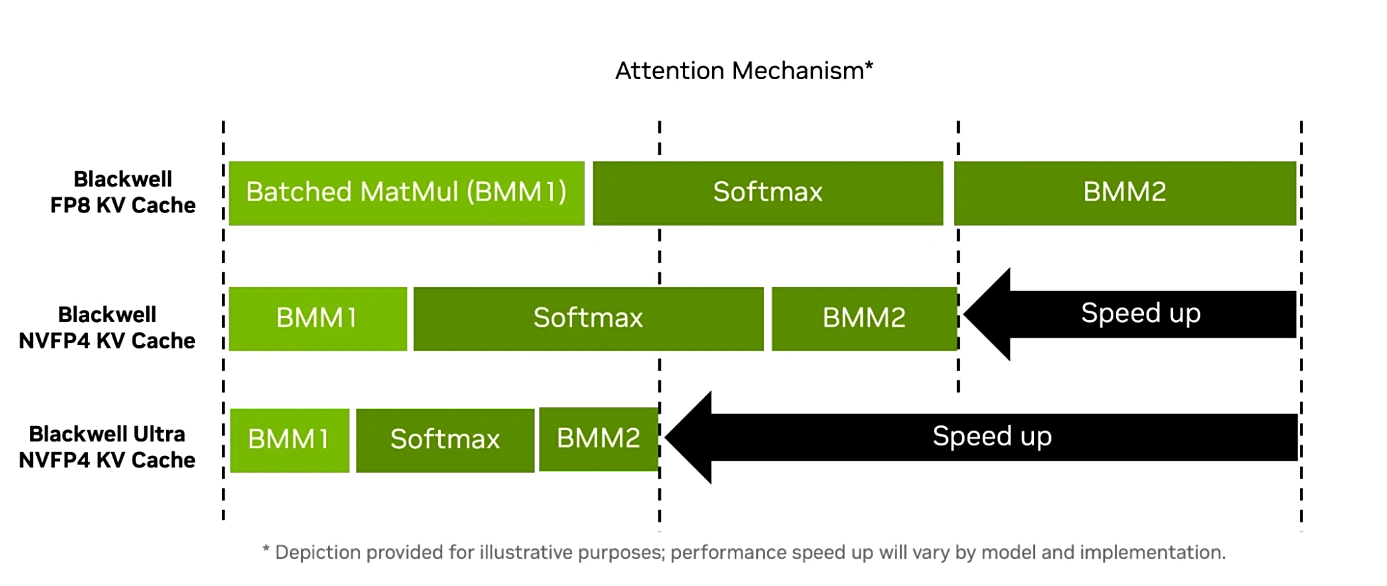
NVIDIA ได้เผยแพร่บล็อกโพสต์ เพื่อเจาะลึกชิป AI ที่เร็วที่สุดของตนอย่าง Blackwell Ultra GB300 ซึ่งมีประสิทธิภาพสูงกว่า GB200 รุ่นก่อนถึง 50%
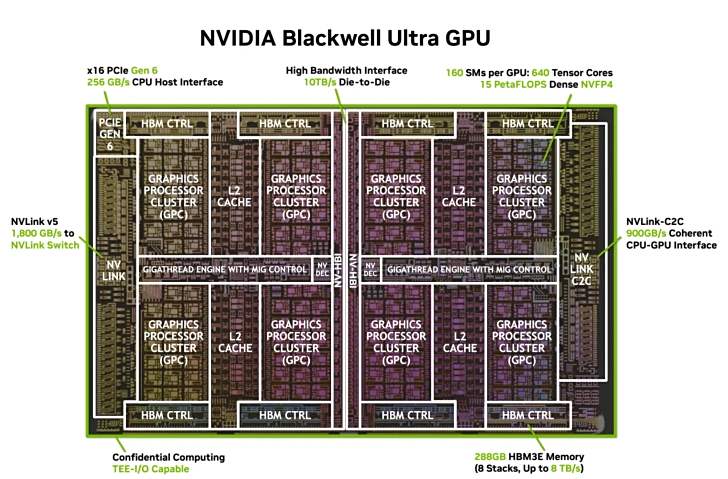
ชิปนี้ใช้ดีไซน์ dual-reticle ประกอบด้วย ทรานซิสเตอร์ 208 พันล้านตัว, 20,000 CUDA Cores, และมาพร้อม หน่วยความจำ HBM3e ขนาด 288GB ที่ให้แบนด์วิดท์สูงถึง 8TB/s
GB300 ใช้การออกแบบ dual-mask (dual-mask คือการออกแบบชิปขนาดใหญ่ที่สุดที่สามารถสร้างได้ด้วยการฉายแสงครั้งเดียว โดยอาศัยเทคโนโลยีเชื่อมต่อให้ทำงานร่วมกันเหมือนเป็นชิปเดียว) ซึ่งเชื่อมต่อชิปใหญ่สองตัวเข้าด้วยกันเป็น GPU เดียว ผ่าน NV-HBI ที่มีแบนด์วิดท์สูงถึง 10TB/s
ผลิตด้วยกระบวนการ TSMC 4NP มีทรานซิสเตอร์รวม 208 พันล้านตัว, 160 SM units, แต่ละ SM มี 128 CUDA Cores รวมทั้งหมด 20,480 CUDA Cores และ 640 Tensor Cores เจเนอเรชัน 5 พร้อม TMEM 40MB
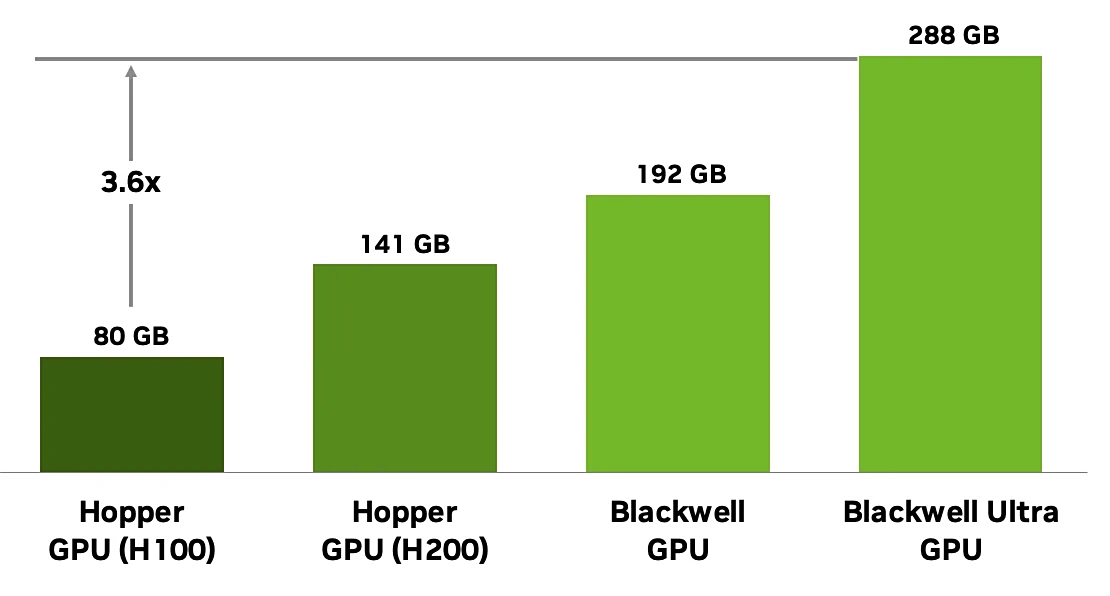
ด้านหน่วยความจำ GB300 มาพร้อม HBM3e 288GB ให้แบนด์วิดท์ 8TB/s ซึ่งมากกว่า 192GB ของ GB200 อย่างเห็นได้ชัด โดยหน่วยความจำแบบซ้อน 8 ชุดถูกเชื่อมต่อผ่านบัสกว้าง 8192-bit รองรับโมเดลที่มีพารามิเตอร์กว่า 300 พันล้านตัว ทำให้ได้ความยาว context ที่มากขึ้นและประสิทธิภาพการประมวลผลสูงขึ้น
Blackwell Ultra รองรับ NVLink เจเนอเรชัน 5 ให้แบนด์วิดท์สองทิศทางสูงถึง 1.8TB/s ต่อ GPU และเชื่อมต่อได้สูงสุด 576 GPUs อินเทอร์เฟซ PCIe Gen6 ให้แบนด์วิดท์ 256GB/s พร้อมรองรับ NVLink-C2C สำหรับทำงานร่วมกับ Grace CPUs ฟีเจอร์ระดับองค์กรยังรวมถึง Multi-Instance GPU (MIG), ระบบ secure computing, และการทำงานด้าน AI predictive operations
ในระดับระบบ ชุด Grace Blackwell Ultra superchip เชื่อมต่อ Grace CPU เข้ากับ GPU สองตัว เพื่อสร้างระบบ GB300 NVL72 rack ที่มีพลังประมวลผลสูงสุดถึง 1.1 EFLOPS FP4
ด้านความปลอดภัยและการจัดการ GB300 มาพร้อม GigaThread scheduling engine รุ่นใหม่, รองรับ MIG สำหรับการแบ่งสรรหน่วยความจำอย่างยืดหยุ่น, และเพิ่มฟีเจอร์ Confidential Computing และ TEE-I/O เพื่อรับประกันความปลอดภัยของโมเดล AI และข้อมูล
ที่มา : IT Home