



NVIDIA RTX AI Garage – วิธีรัน LLMs ยอดนิยมบนพีซีของคุณ
ปัจจุบันมีผู้ใช้จำนวนมากขึ้นที่เลือก รันโมเดลภาษาขนาดใหญ่ (LLMs) บนพีซีของตนเองโดยตรง เพื่อลดค่าใช้จ่ายจากการสมัครสมาชิก พร้อมทั้งได้ ความเป็นส่วนตัวและการควบคุมที่มากขึ้น สำหรับโปรเจกต์ของตัวเอง ด้วยการมาถึงของโมเดลแบบ open weight รุ่นใหม่ และเครื่องมือฟรีที่ช่วยให้สามารถรันได้แบบ local ผู้ใช้จำนวนมากจึงเริ่มอยากทดลอง AI บน โน้ตบุ๊กหรือเดสก์ท็อป ของตัวเอง RTX GPU ช่วยเร่งประสบการณ์เหล่านี้ให้ เร็ว ลื่น และตอบสนองฉับไว อีกทั้งด้วยการอัปเดต Project G-assist ผู้ใช้โน้ตบุ๊กยังสามารถสั่งงานพีซีได้ด้วย เสียงหรือข้อความ ที่ขับเคลื่อนด้วย AI
บล็อก RTX AI Garage ล่าสุดของ NVIDIA ได้ชี้ให้เห็นว่า นักเรียน นักพัฒนา และผู้สนใจ AI สามารถเริ่มต้นใช้ LLMs บนพีซีได้ตั้งแต่วันนี้ เช่น:
-
Ollama: วิธีที่เข้าถึงง่ายที่สุด เครื่องมือโอเพ่นซอร์สที่มาพร้อมอินเทอร์เฟซเรียบง่ายในการรันและโต้ตอบกับ LLMs ผู้ใช้สามารถลากไฟล์ PDF ลงใน prompt, พูดคุยโต้ตอบ, หรือแม้แต่ทดลอง workflow แบบมัลติโหมดที่ผสมผสานข้อความกับภาพได้
-
AnythingLLM: สร้างผู้ช่วย AI ส่วนตัว ทำงานบน Ollama โดยสามารถโหลดโน้ต, สไลด์, หรือเอกสารต่าง ๆ เพื่อสร้าง “ติวเตอร์ส่วนตัว” ที่ช่วยทำข้อสอบย่อยหรือแฟลชการ์ดสำหรับการเรียนรู้ได้ — ใช้งานแบบส่วนตัว, เร็ว และฟรี
-
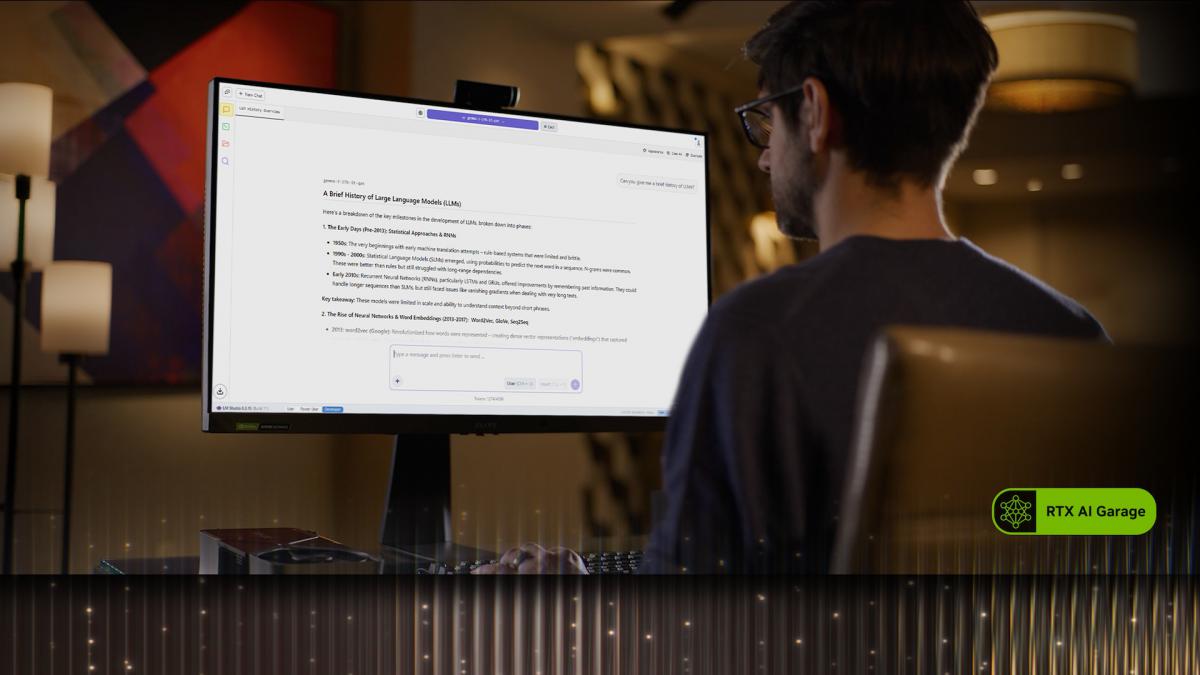
LM Studio: สำรวจโมเดลมากมาย ทำงานบนเฟรมเวิร์กยอดนิยม llama.cpp และมาพร้อมอินเทอร์เฟซใช้งานง่ายสำหรับการรันโมเดลแบบ local ผู้ใช้สามารถโหลด LLMs หลากหลาย, พูดคุยกับโมเดลแบบเรียลไทม์ หรือแม้แต่รันเป็น local API เพื่อนำไปผสานกับโปรเจกต์ของตัวเอง
-
Project G-Assist: ควบคุมพีซีด้วย AI การอัปเดตล่าสุดช่วยให้ผู้ใช้สั่งงานปรับแบตเตอรี่, พัดลม และโหมดประสิทธิภาพได้ด้วยเสียงหรือข้อความ
ความก้าวหน้าล่าสุดของ RTX AI PCs มีดังนี้:
-
Ollama เร็วขึ้นมากบน RTX: การอัปเดตใหม่ช่วยเพิ่มประสิทธิภาพสูงสุดถึง 50% สำหรับโมเดล gpt-oss-20B ของ OpenAI และเร็วขึ้น 60% สำหรับโมเดล Gemma 3 พร้อมการจัดตารางโมเดลที่ฉลาดขึ้นเพื่อลดปัญหาหน่วยความจำและเพิ่มประสิทธิภาพการทำงานแบบหลาย GPU
-
llama.cpp และ GGML ถูกปรับแต่งสำหรับ RTX: การอัปเดตล่าสุดช่วยให้ inference เร็วและมีประสิทธิภาพยิ่งขึ้น รวมถึงรองรับ NVIDIA Nemotron Nano v2 9B, เปิดใช้งาน Flash Attention เป็นค่าเริ่มต้น และเพิ่มการปรับแต่ง CUDA kernel
-
G-Assist v0.1.18 สามารถดาวน์โหลดได้แล้วผ่าน NVIDIA App มาพร้อมคำสั่งใหม่สำหรับผู้ใช้โน้ตบุ๊ก และการปรับปรุงคุณภาพการตอบกลับ
-
Microsoft เปิดตัว Windows ML ที่ผนวก TensorRT ของ NVIDIA สำหรับ RTX acceleration ทำให้ inference เร็วขึ้นถึง 50%, การ deploy ง่ายขึ้น และรองรับทั้ง LLMs, diffusion และโมเดลอื่น ๆ บน Windows 11 PCs
สามารถติดตามรายละเอียดเพิ่มเติมได้ใน RTX AI Garage ประจำสัปดาห์นี้
