NVIDIA ใช้เวที CES 2026 ประกาศแพลตฟอร์ม AI สำหรับดาต้าเซ็นเตอร์รุ่นถัดไปอย่างเป็นทางการในชื่อ Rubin โดยสแต็กนี้สร้างขึ้นจากชิปใหม่ทั้งหมด 6 ตัว และจะถูกนำไปใช้งานในระบบอย่าง Vera Rubin NVL72 rack และแพลตฟอร์มเซิร์ฟเวอร์ HGX Rubin NVL8
หัวใจหลักคือ Rubin GPU ซึ่งมีทรานซิสเตอร์มากถึง 336 พันล้านตัว ใช้โครงสร้างแบบ สองรีทิเคิลได (dual reticle dies)
NVIDIA ระบุสมรรถนะไว้ที่สูงสุด 50 PFLOPs สำหรับ NVFP4 inference และ 35 PFLOPs สำหรับ NVFP4 training โดยสไลด์ของบริษัทระบุว่าแรงกว่า Blackwell ถึง 5 เท่าในงาน inference และ 3.5 เท่าในงาน training
Rubin GPU เปลี่ยนมาใช้หน่วยความจำ HBM4 รองรับสูงสุด 288GB ต่อ GPU และมีแบนด์วิดท์หน่วยความจำสูงสุด 22 TB/s
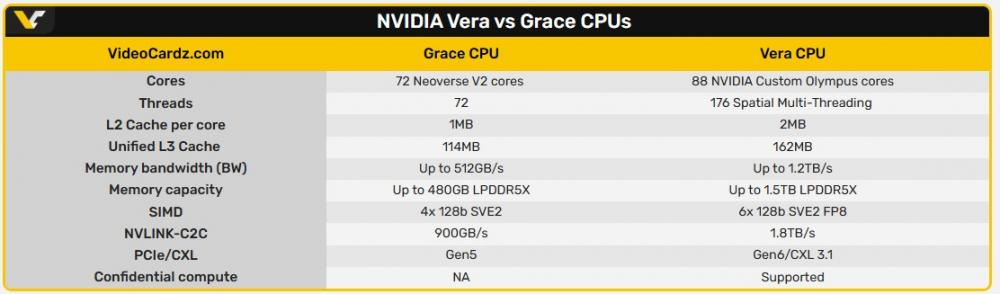
ฝั่ง CPU จะเป็น Vera CPU มีทรานซิสเตอร์ 227 พันล้านตัว ใช้คอร์ Arm แบบปรับแต่งเองในชื่อ “Olympus”
Vera มาพร้อม 88 คอร์ 176 เธรด โดยใช้เทคโนโลยี NVIDIA Spatial Multi-Threading รองรับหน่วยความจำ LPDDR5x (SOCAMM) สูงสุด 1.5TB และแบนด์วิดท์หน่วยความจำสูงสุด 1.2 TB/s
แบนด์วิดท์แบบ coherent ผ่าน NVLink-C2C อยู่ที่ 1.8 TB/s และ NVIDIA อ้างว่าประสิทธิภาพด้าน data processing, compression และ CI/CD ดีขึ้นถึง 2 เท่า เมื่อเทียบกับ Grace
สำหรับการขยายระบบแบบ scale-up จะใช้ NVLink 6 ซึ่งให้แบนด์วิดท์ GPU-to-GPU แบบสองทิศทาง 3.6 TB/s ต่อ GPU และทั้งแร็ก NVL72 จะมีแบนด์วิดท์รวมสูงถึง 260 TB/s
สวิตช์ NVLink 6 ยังถูกวางตำแหน่งเป็นส่วนหนึ่งของ compute fabric โดยมีแบนด์วิดท์รวม 28.8 TB/s และพลังประมวลผลเครือข่าย 14.4 TFLOPS FP8 ต่อ switch tray
ในฝั่ง scale-out NVIDIA เปิดตัว ConnectX-9 และ BlueField-4
ConnectX-9 รองรับสูงสุด 1.6 Tb/s ต่อ Rubin GPU ขณะที่ BlueField-4 ถูกวางตำแหน่งเป็น DPU ระดับ 800 Gb/s
ส่วน Spectrum-X Ethernet Photonics จะทำงานร่วมกับ Spectrum-6 บนโครงสร้างสวิตช์ 102.4 Tb/s พร้อมเทคโนโลยี co-packaged optics
ระดับแร็ก ระบบเรือธงคือ Vera Rubin NVL72 ซึ่งประกอบด้วย 72 Rubin GPU และ 36 Vera CPU เชื่อมต่อกันผ่าน NVLink 6
ตัวเลขจาก NVIDIA ระบุสมรรถนะไว้ที่
-
3.6 EFLOPS สำหรับ NVFP4 inference
-
2.5 EFLOPS สำหรับ training
-
หน่วยความจำ HBM4 รวม 20.7TB
-
หน่วยความจำ LPDDR5x รวม 54TB
-
แบนด์วิดท์ HBM รวมสูงถึง 1.6 PB/s
ด้านประสิทธิภาพต่อค่าใช้จ่าย NVIDIA ระบุว่า Rubin สามารถลดต้นทุน AI ได้อย่างมาก เช่น
-
ต้นทุน inference ต่อโทเค็นลดลงสูงสุด 10 เท่า
-
ใช้ GPU น้อยลง 4 เท่า สำหรับการเทรน MoE เมื่อเทียบกับ Blackwell
และในสไลด์หนึ่งยังระบุว่า MoE inference มีต้นทุนต่อโทเค็นประมาณ 1 ใน 7 เมื่อเทียบกับ GB200
NVIDIA ระบุว่า Rubin เข้าสู่ การผลิตเต็มรูปแบบแล้วในไตรมาส 1 ปี 2026 แม้แนวทางเดิมจะชี้ไปที่ครึ่งหลังของปี 2026
การวางจำหน่ายผ่านพาร์ตเนอร์ยังคงระบุไว้ใน ครึ่งหลังของปี 2026 และ NVIDIA ระบุว่ามีการใช้งานช่วงต้นปี 2026 แล้วกับ AWS, Google Cloud, Microsoft และ Oracle Cloud รวมถึงพันธมิตร NVIDIA Cloud อย่าง CoreWeave, Lambda, Nebius และ Nscale
ที่มา: VideoCardz